Что мы у себя делаем, если приходит чужой проект:
- Собираем все вводные данные: git, тз, ссылки, доступы
- Готовим шаблон и документ для анализа
- Читаем и пишем (никакой магии)
Вводные данные
Хорошо, если для проекта есть git-репозиторий и видна в нём история разработки. Это может быть доступ в gitlab / github / bitbucket. Но может быть архив, в котором есть папка .git.
Хуже, если истории. Один архив с файлами проекта - тревожный показатель. Может оказаться что в нём нет исходных кодов, а только собранный проект. Тогда не всё можно поправить в будущем.
Помимо кода, могут быть ещё важные вещи:
- техническое задание;
- бриф;
- договор;
- документация;
- ссылка на дизайн или набор макетов.
Не всегда проект можно восстановить, если есть исходный код. Зачастую для него нужна и база данных и набор файлов-картинок (их в гите может не быть). Bitrix сайт, без копии базы данных - точно не запустить. Получить их самостоятельно можно, если проект где-то работает и есть доступ к серверу.
Документы на анализ
Двух видов документы готовим:
- таблицы разные: анализ по файлам, назначение папок, перечень зависимостей;
- текстовый документ для записей по проекту
Таблицы
Удобны для чтения кода и понимания “сколько ещё анализировать осталось”.
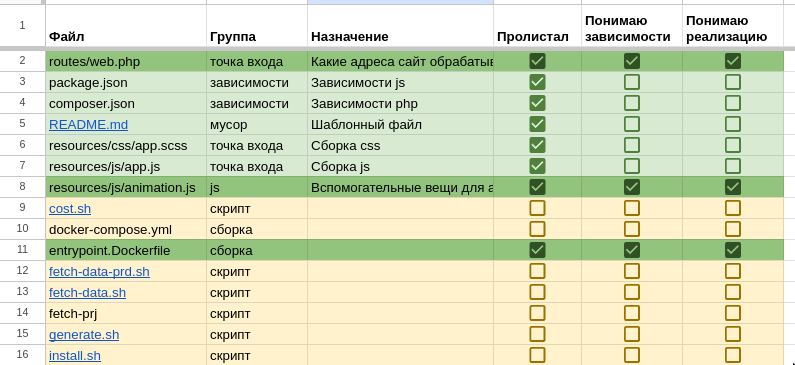
Собираем список файлов, скажем так:
find . -type f > files.txt
И список каталогов:
find . -type d > dirs.txt
Хорошо ещё сделать таблицу по зависимостям в проекте (package.json / composer.json). Каждую зависимость стоит проверить на лицензию: лицензия MIT - хорошо, AGPL / GPL - не всем подойдут в коммерческих проектах.
Перечень зависимостей поможет понять на чём проект написан, какие разработчики потребуются. Для разработки интерфейса - большая разница между react-/angular-/vue-разработчиками.
Документ с заметками
Не всё в таблицу удобно собирать. Скриншоты, большие комментарии - проще оформить как текстовый документ.
У нас обычно разделы в нём следующие:
- предоставленные материалы - ссылки где найти всё по проекту, тестовые среды, макеты - ориентир по материалам;
- связанные документы - ссылки на все таблицы, которые составили при анализе. И пояснение к каждой таблице - зачем она и что в ней;
- объём кодовой базы - сколько файлов в проекте, сколько коммитов, сколько разработчиков участвовало. Здесь же можно сравнить с каким-либо opensource проектом похожим;
- технологии на чём проект написан, от чего зависит;
- ошибки и баги собранные при тестировании;
- общее впечатление от кодовой базы.
И рутина…
Открываем каждый файл, просматриваем, отмечаем если что-то интересное.
Запускаем cloc (программа бесплатная, что посчитает строки кода) для разных папок:
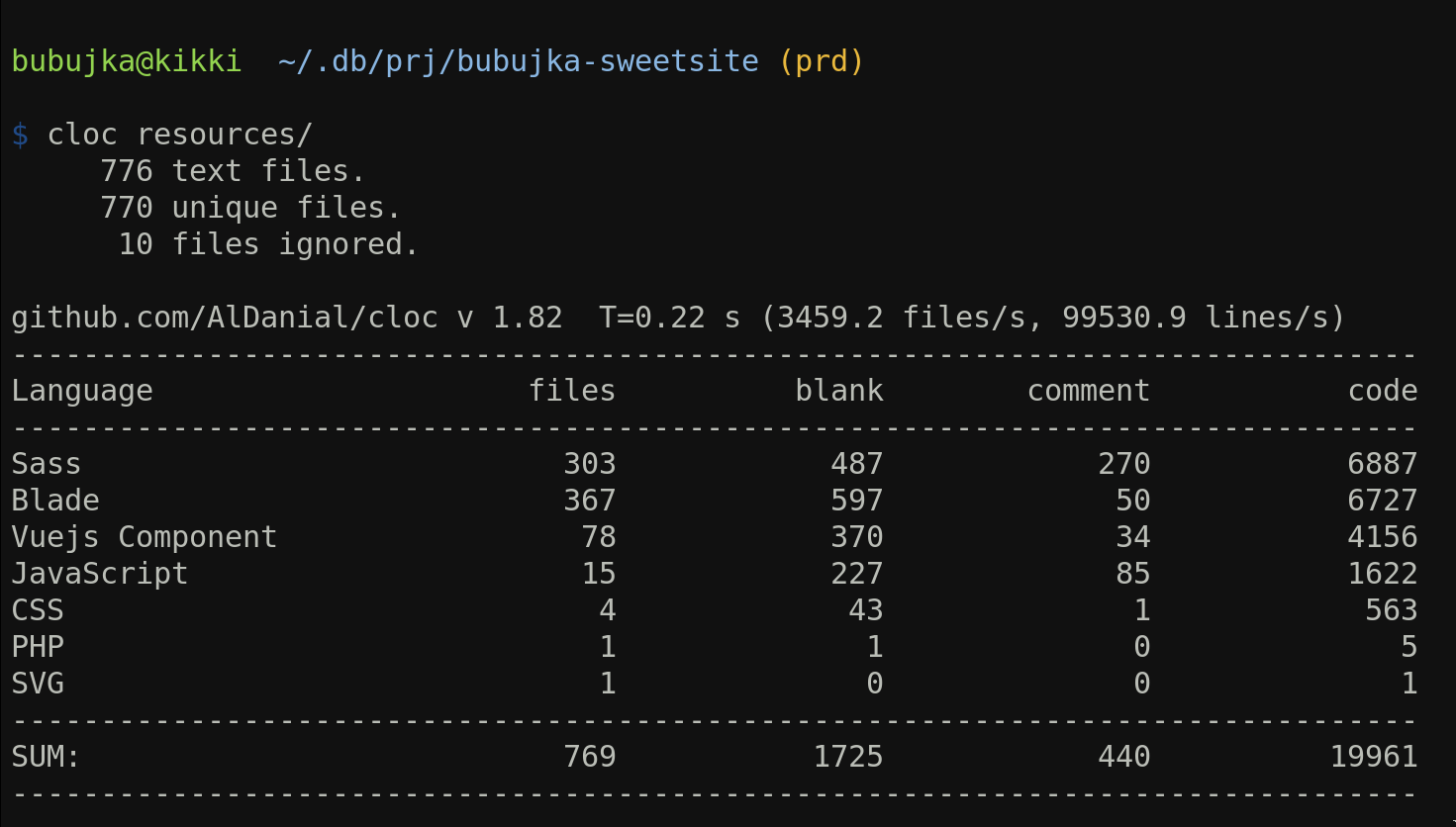
Делаем заметки, пишем выводы.
Что для проектов интересно понять:
- какие точки входа в проекте. routes/*.php для laravel, app.js, app.scss для вёрстки
- На чём проект написан
- Какие системные зависимости нужны: mysql/postgresql/ redis/ rabbit
- Есть ли фоновые задачи
- Какие версии языков программирования нужны
- Сколько кода для model-view-controller
- На чём написан интерфейс (vue / react / angular / jquery или просто html), sass/pug/less
- Описан ли процесс сборки: .gitlab-ci.yml, bitbucket-pipelines.yml
- Насколько проработана инфраструктура: docker, kubernetes
- Как велась разработка - формальные сообщения у коммитов - хороший показатель. Ветки, номера задач в проекте - тоже.
- Как запустить для режима разработки (npm start?)
- Как подготовить релиз для боя (npm run build?)
Перечитываем, обсуждаем, дополняем.
 Алексей Камынин
Алексей Камынин
 Светлана Макарова
Светлана Макарова